
Highlights
- As ferramentas de AutoML parecem ter grande potencial de contribuição no cotidiano de um time de Data Science/Machine Learning, porém nas etapas mais adiantadas do processo de desenvolvimento e realease de modelos;
- Etapas de entendimento do problema e engenharia de features são pouco impactados por este tipo de ferramentas;
- Analisando o
auto-sklearn, o processo automatizado tem umas carga de aprendizado bastante grande e exige um certo processo exploratório inicial para redução do espaço de busca de algoritmos e parâmetros para facilitar uma segunda etapa de otimização de hiperparâmetros propriamente dito; - O código usado na exploração do
auto-sklearnestá disponível em um repositório público na minha conta do GitHub;
O artigo em si
Nos últimos meses tenho me dedicado à identificar e otimizar o cotidiano de times de Machine Learning & AI com processos, políticas e novas tecnologias. Um dos pontos que tenho avaliado em mais detalhes é a utilização de bibliotecas de automated machine learning (AutoML) para auxiliar o processo de encontrar o melhor modelo possível em desenvolvimento. Após algumas análises, decidi compartilhar algumas de minhas impressões neste artigo.
“I have a dream that one day my product is going to be supplied by self-assembled machine learning models.” (Algum C-level de alguma empresa anunciando que agora são AI-first e que serão referência em AI nos próximos 2 anos).
O que será considerado como um modelo neste artigo?
Na minha perspectiva (e acredito que não só minha), um modelo de Machine Learning é composto por três partes fundamentais. Já alerto que simplificarei bastante a descrição das partes para facilitar o entendimento de quem não tem muito vocabulário deste contexto.
- Dataset, que contém os dados com todas as features e registros que serão utilizados para o treinamento e validação do modelo, independente do fato de ser supervisionado ou não;
- Algoritmo/Ensemble, que é a ferramenta que será usada para encontrar determinados padrões nos dados do dataset e ser capaz de utilizar tais padrões para processar novos registros que sejam requisitados para o modelo e realizar uma predição (classificação, regressão, pattern recognition, etc.).
- Hiper-parâmetros: os parâmetros a serem usados pelo algoritmo e que serão otimizados (também chamado de tunning) de forma a obter maior capacidade de predição de um algoritmo sobre um determinado conjunto de dados. Alguns pontos importantes são:
- Existem parâmetros tanto do algoritmo quanto do dataset (por exemplo, balanço entre classes positivas e negativas em um caso de aprendizado supervisionado) e de algoritmo (por exemplo, a profundidade máxima de uma árvore de decisão);
- Um mesmo algoritmo aplicado a dois datasets diferentes pode (e provavelmente irá) requerer diferentes valores de parâmetros para alcançar a performance ótima;
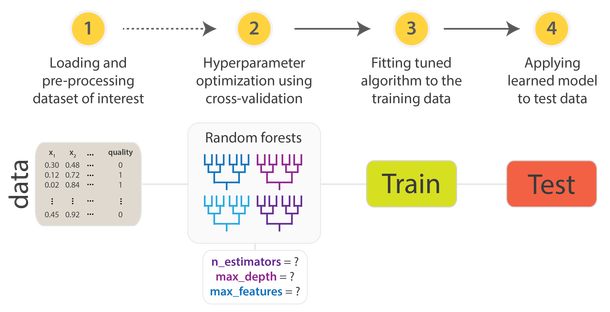 Diagrama simplificado sobre as etapas da criação de um modelo de ML
Diagrama simplificado sobre as etapas da criação de um modelo de ML
Qual a minha compreensão sobre AutoML neste momento?
Ao explorar algumas bibliotecas de AutoML como o auto-sklearn, H2O, Google Cloud AutoML e outras, identifiquei, de maneira geral, o seguinte comportamento em todas elas:
- oferecem funcionalidades de Engenharia de Features que aplicam novas representações de um mesmo dado (por exemplo, fazer One Hot Encoding de uma feature categórica) mas não abordam muito bem a relevância delas;
- oferecem um grande portfolio de algoritmos que serão utilizados na busca pelo melhor modelo;
- permitem customizações de métricas e de algoritmos para permitir que os usuários utilizem a ferramenta de AutoML como uma plataforma de otimização que pode ser encaixada nas particularidades de uma empresa;
Dessa forma, as ferramentas que explorei não agregam muito valor à etapa de engenharia de features, com foco explícito no tunning de algoritmos e hiper-parâmetros. Ao meu ver, isso limita bastante a magnitude do impacto que este tipo de ferramenta tem na automação do processo de criação de um modelo. Eis alguns pontos que sustentam esta minha opinião:
- Por mais que muitos acreditem que um modelo de ML é um data monster que vai processar milhares de features com dados de usuários dos últimos 10 anos e se tornar um oráculo das predições, não é o que acontece de fato. A etapa de tratamento de dados, construção de features e identificação das mais relevantes compõe os maiores desafios na construção de modelos;
- Alguns algoritmos possuem premissas as quais os dados precisam respeitar para que sejam aplicados adequadamente (por exemplo, o LDA assume que os dados tenham distribuição normal e que ambas as classes possuam uma mesma matriz de covariância). A automação apenas do processo de tunning pode contribuir com a negligência deste tipo de validação;
Um breve exemplo: algoritmos vanilla VS auto-sklearn
Para exemplificar de maneira mais tangível o valor percebido durante a minha exploração das bibliotecas, eu mostrarei um exemplo simples que construi para explorar como o auto-sklearn funciona e o quanto ele contribuiria para um modelo construído sobre dados que já conheço. Portanto, eu tomei como base um modelo que fiz alguns anos atrás, para fins didáticos, para prever o gênero de uma música a partir de sua letra. Sendo assim, usei os mesmos dados e gerei as mesmas features (tf-idf dos 200 tokens mais relevantes) para treinar um modelo. Neste artigo eu não entrarei em detalhes sobre a geração destas features.
Vanilla Decision Tree
Para ter um baseline simples, vou criar um modelo usando Árvore de Decisão (Decision Tree) com os parâmetros padrão do scikit-learn.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(train_features, train_target)
predicted_target = model.predict(test_features)
print("Accuracy score: ", sklearn.metrics.accuracy_score(test_target, predicted_target))
O resultado impresso por este trecho de código é:
Accuracy score: 0.6412903225806451
Sendo assim, um modelo criado sobre este conjunto de features usando uma árvore de decisão “padrão” gerou um modelo com 64,1% de acurácia.
Vanilla Random Forests
Da mesma forma que usei uma árvore de decisão sem otimização de hiper-parâmetros como baseline, farei o mesmo com Random Forests.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(train_features, train_target)
predicted_target = model.predict(test_features)
print("Accuracy score: ", sklearn.metrics.accuracy_score(test_target, predicted_target))
O resultado impresso por este trecho de código é:
Accuracy score: 0.7896774193548387
A acurácia obtida por este modelo foi de 79,0%, consideravelmente maior que o modelo vanilla de Árvore de Decisão.
auto-sklearn
O auto-sklearn é uma biblioteca construída em cima do scikit-learn e que ganhou relevância ao ser apresentado no NIPS e também ao vencer um desafio de AutoML. Pela simplicidade do propósito desta exploração, o escolhi para fazer alguns testes.
Algumas premissas importantes para interpretar melhor o que vem a seguir:
- Eu executei os pipelines em meu computador pessoal e para fins de exploração. Sendo assim, não fiz longas e extensivas explorações dos recursos da biblioteca;
- De propósito, eu explorei a biblioteca de maneira mais naive e tentando simular como pessoas sem tanta experiência neste tipo de modelagem fariam a exploração;
Show me the code.
import autosklearn.classification
import yaml
with open('config.yml') as f:
settings = yaml.load(f, Loader=yaml.FullLoader)
automl = autosklearn.classification.AutoSklearnClassifier(**settings)
automl.fit(train_features, train_target)
predicted_target = automl.predict(test_features)
print(automl.show_models())
print(automl.sprint_statistics())
print("Accuracy score", sklearn.metrics.accuracy_score(test_target, predicted_target))
Para executar os pipelines, eu montei as configurações em arquivos yaml com os parâmetros a serem usados pelo pipeline do automl.
config.yml sem ensemble
Na primeira tentativa, vou tentar encontrar um modelo simples com apenas um conjunto de algoritmo + hiperparâmetros. Para isso, usei as configurações abaixo.
n_jobs: 2
per_run_time_limit: 120 # 2 minutes
time_left_for_this_task: 1800 # 30 minutes
include_preprocessors: ['no_preprocessing']
ensemble_size: 1 # to get only a model, not an ensemble
[(1.000000, SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'bernoulli_nb', 'data_preprocessing:categorical_transformer:categorical_encoding:__choice__': 'no_encoding', 'data_preprocessing:categorical_transformer:category_coalescence:__choice__': 'no_coalescense', 'data_preprocessing:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessing:numerical_transformer:rescaling:__choice__': 'normalize', 'feature_preprocessor:__choice__': 'no_preprocessing', 'classifier:bernoulli_nb:alpha': 10.12857981579372, 'classifier:bernoulli_nb:fit_prior': 'False'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})),
]
O melhor modelo encontrado nesta execução foi o bernoulli_nb (Naive Bayes classifier for multivariate Bernoulli). Até aí, nenhum problema.
As características da execução do pipeline foram:
Metric: accuracy
Best validation score: 0.786458
Number of target algorithm runs: 1903
Number of successful target algorithm runs: 1880
Number of crashed target algorithm runs: 9
Number of target algorithms that exceeded the time limit: 5
Number of target algorithms that exceeded the memory limit: 9
Vamos às métricas:
Accuracy score: 0.7638709677419355
Ou seja, o modelo encontrado automaticamente pelo auto-sklearn foi melhor que o vanilla Decision Tree porém pior que o vanilla Random Forest.
config.yml com ensemble
Para explorar melhor as funcionalidades da biblioteca, criei um novo pipeline onde busco como resultado final um ensemble com 3 modelos para maximizar a acurácia da classificação. Abaixo seguem as configurações deste novo pipeline:
n_jobs: 2
per_run_time_limit: 120 # 2 minutes
time_left_for_this_task: 1800 # 30 minutes
include_preprocessors: ['no_preprocessing']
ensemble_size: 3 # to get only a model, not an ensemble
As características desse ensemble foram:
[(0.333333, SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'sgd', 'data_preprocessing:categorical_transformer:categorical_encoding:__choice__': 'no_encoding', 'data_preprocessing:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer', 'data_preprocessing:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessing:numerical_transformer:rescaling:__choice__': 'quantile_transformer', 'feature_preprocessor:__choice__': 'no_preprocessing', 'classifier:sgd:alpha': 1.1309190654192295e-07, 'classifier:sgd:average': 'True', 'classifier:sgd:fit_intercept': 'True', 'classifier:sgd:learning_rate': 'optimal', 'classifier:sgd:loss': 'perceptron', 'classifier:sgd:penalty': 'elasticnet', 'classifier:sgd:tol': 0.0003060155962964433, 'data_preprocessing:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.006195858518768137, 'data_preprocessing:numerical_transformer:rescaling:quantile_transformer:n_quantiles': 1929, 'data_preprocessing:numerical_transformer:rescaling:quantile_transformer:output_distribution': 'uniform', 'classifier:sgd:l1_ratio': 0.0018872923177367703},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})),
(0.333333, SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'extra_trees', 'data_preprocessing:categorical_transformer:categorical_encoding:__choice__': 'no_encoding', 'data_preprocessing:categorical_transformer:category_coalescence:__choice__': 'no_coalescense', 'data_preprocessing:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessing:numerical_transformer:rescaling:__choice__': 'quantile_transformer', 'feature_preprocessor:__choice__': 'no_preprocessing', 'classifier:extra_trees:bootstrap': 'False', 'classifier:extra_trees:criterion': 'entropy', 'classifier:extra_trees:max_depth': 'None', 'classifier:extra_trees:max_features': 0.23993615625255216, 'classifier:extra_trees:max_leaf_nodes': 'None', 'classifier:extra_trees:min_impurity_decrease': 0.0, 'classifier:extra_trees:min_samples_leaf': 1, 'classifier:extra_trees:min_samples_split': 10, 'classifier:extra_trees:min_weight_fraction_leaf': 0.0, 'data_preprocessing:numerical_transformer:rescaling:quantile_transformer:n_quantiles': 1169, 'data_preprocessing:numerical_transformer:rescaling:quantile_transformer:output_distribution': 'uniform'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})),
(0.333333, SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'qda', 'data_preprocessing:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding', 'data_preprocessing:categorical_transformer:category_coalescence:__choice__': 'no_coalescense', 'data_preprocessing:numerical_transformer:imputation:strategy': 'most_frequent', 'data_preprocessing:numerical_transformer:rescaling:__choice__': 'standardize', 'feature_preprocessor:__choice__': 'no_preprocessing', 'classifier:qda:reg_param': 0.40061768323123503},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})),
]
Resumindo, o ensemble é composto por um modelo SGD - Stochastic Gradient Descendent, um Extra Trees e um QDA - Quadratic Discriminant Analysis, cada um com o respectivo conjunto de hiperparâmetros listados no snippet acima.
As características da execução do pipeline foram:
Metric: accuracy
Best validation score: 0.786458
Number of target algorithm runs: 1949
Number of successful target algorithm runs: 1908
Number of crashed target algorithm runs: 10
Number of target algorithms that exceeded the time limit: 6
Number of target algorithms that exceeded the memory limit: 25
Vamos à acurácia:
Accuracy score: 0.7316129032258064
Ou seja, o ensemble obteve uma acurácia de 73,2% que, quando comparada aos casos anteriores, nos dá o seguinte ranking:
- Vanilla Random Forest
- AutoML sem ensemble
- AutoML com ensemble
- Vanilla Decision Tree
config.yml otimizando apenas o Random Forest
Como terceira tentativa, decidi explorar um pipeline para otimização apenas do Random Forest usando as configurações abaixo:
n_jobs: 2
per_run_time_limit: 60 # 1 minute
time_left_for_this_task: 1200 # 20 minutes
include_preprocessors: ['no_preprocessing']
include_estimators: ['random_forest'] # include only Random Forest
ensemble_size: 3 # to get only a model, not an ensemble
O melhor modelo encontrado pelo pipeline foi:
[(1.000000, SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'random_forest', 'data_preprocessing:categorical_transformer:categorical_encoding:__choice__': 'no_encoding', 'data_preprocessing:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer', 'data_preprocessing:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessing:numerical_transformer:rescaling:__choice__': 'normalize', 'feature_preprocessor:__choice__': 'no_preprocessing', 'classifier:random_forest:bootstrap': 'False', 'classifier:random_forest:criterion': 'gini', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.14928991954179588, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 2, 'classifier:random_forest:min_samples_split': 8, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessing:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.010000000000000004},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})),
]
Ao olhar os parâmetros usados neste modelo, é possível observar que foram poucas as customizações de parâmetros realizadas, o que resulta em um modelo razoavelmente próximo ao vanilla Random Forest.
As características da execução do pipeline foram:
Metric: accuracy
Best validation score: 0.786458
Number of target algorithm runs: 1260
Number of successful target algorithm runs: 1253
Number of crashed target algorithm runs: 0
Number of target algorithms that exceeded the time limit: 7
Number of target algorithms that exceeded the memory limit: 0
Os números acima mostram que o pipeline executou mais de 1200 configurações diferentes de modelo, com alguns poucos casos que excederam o limite de tempo de 1 minuto por modelo.
Vamos às métricas:
Accuracy score: 0.8025806451612904
Ou seja, este pipeline resultou em um modelo que alcançou uma acurácia de 80,3%, o maior alcançado até o momento. Entretanto, o ganho não foi muito substancial (1,6%) e o resultado final foi um modelo muito parecido com o vanilla.
Algumas conclusões e próximos passos
- Das opções testadas, o melhor modelo obtido foi a partir de um pipeline do
auto-sklearnotimizando apenas Random Forests. Entretanto, o resultado de acurácia é muito semelhante ao vanilla Random Forest; - Há uma curva de aprendizado considerável para extrair o melhor da biblioteca;
- É possível que eu tenha dedicado pouco tempo de computação para este tipo de otimização pelo
auto-sklearn. Se for o caso, acredito que este tipo de “necessidade” poderia ficar mais explícito nas documentações para que os usuários tivessem uma expectativa mais realista sobre o que precisariam para extrair valor da biblioteca;