
Este será o primeiro artigo de uma série chamada “Do fundamento à aplicação”, que abordará, através de exemplos e pequenas aplicações, a importância de conhecer bem os fundamentos das metodologias e ferramentas que utilizamos em nosso dia-a-dia para que possamos fazer boas escolhas na hora de criar e implementar soluções, sejam elas técnicas ou gerenciais. Além da conexão entre fundamentos e aplicações, haverá uma tentativa de traduzir alguns conceitos para uma linguagem menos formal e técnica.
O tema estreante será uma estrutura de dados bastante interessante e de muita utilidade: as Árvores Métricas (fundamento) cuja aplicação é um bom e velho conhecido de todos nós — corretor ortográfico.
Alguns fundamentos importantes
O principal propósito deste tipo de conteúdo e mostrar, além de trechos de código mostrando como construir uma aplicação, o que está “embaixo do capô” deste código, permitindo um entendimento mais completo da solução, além de maiores capacidades de extensão de partes específicas para resolver problemas que são próximos a este.
Nesta seção, serão abordados, de maneira resumida e com referências para que vocês possam se aprofundar nos temas, alguns fundamentos que serão a base para a construção da aplicação em questão — um corretor ortográfico. Os temas serão:
- Conjuntos e domínios de dados;
- Espaços métricos e Árvores;
- Distância de edição;
- Árvores de BK;
Conjuntos e Espaços Métricos
Suponha um conjunto de dados com 1000 pontos 2D (x, y), amostra a qual será chamada A, cujos valores de x e y variem entre 0 e 1([0,1]²), intervalo o qual pode ser chamado de domínio (D).
import random
import pandas as pd
import numpy as np
def generate_random_df_2d(x_size: int, y_size: int) -> pd.DataFrame:
""" Generate a dataframe with dimensions 'x_size' and 'y_size' filled with
random float numbers between 0 and 1
"""
return pd.DataFrame(np.random.random_sample(size=(x_size, y_size)))
Toda vez que um conjunto de objetos, seja o objeto numérico (como o os números inteiros ou reais) ou de outro tipo (palavras, imagens, etc.) ter uma métrica bem definida que pode ser associada, então este conjunto pode ser classificado como um espaço métrico.
Mas o que significa exatamente a tal métrica?
De uma perspectiva mais próximo da matemática, uma métrica existe quando os pontos de um conjunto satisfazem as seguintes condições:
- A distância de um ponto para ele mesmo é zero (0);
- A distância entre dois pontos distintos (A e B) quaisquer é sempre positiva;
- A distância entre os pontos A e B é a mesma entre os pontos B e A;
- A distância entre dois pontos A e B, medida diretamente, é sempre menor ou igual à distância medida entre A e B passando por um ponto C (o que está associado ao Teorema da Desigualdade Triangular, que será usado mais a frente);
Do ponto de vista mais intuitivo, uma métrica remete à distância entre dois pontos (ou objetos), como duas pessoas em uma praça (cuja distância pode ser medida em linha reta) ou duas localizações em uma cidade (cuja distância pode ser medida em linha reta ou através do trajeto a ser percorrido nas ruas). Entretanto, tal conceito também pode ser aplicado a tipos de objetos não muito comuns, como música (que tem métricas bem definidas) ou palavras, que possuem distância de edição entre si (que abordaremos em mais detalhes mais à frente).
 Figura ilustrando o Teorema da Desigualdade Triangular
Figura ilustrando o Teorema da Desigualdade Triangular
Distância de edição
A distância de edição entre duas strings é a contagem de operações que precisam ser realizadas para uma string transforme-se (ou torne-se igual) à outra, sendo que as operações possíveis são:
- Inserção de novo caractere;
- Remoção de caractere;
- Substituição de caractere;
Sendo assim, dado um conjunto de palavras ou sentenças (também chamado de corpus), é possível encontrar a distância de edição entre uma referência (que pode ser uma palavra qualquer de seu corpus). Abaixo segue um trecho simples de código para calcular a distância entre duas palavras:
# Install it by "pip install python-Levenshtein"
from Levenshtein import distance
def calculate_distance(str_1, str_2):
""" Given two string, applies the Levenshtein's method to calculate the
editon distance
"""
return distance(str_1, str_2)
In [1]: calculate_distance(“motocicleta”, “bicicleta”)
Out[1]: 4
Árvores de Burkhard-Keller (BK)
As árvores BK são um tipo de árvore métrica dedicadas a espaços métricos discretos, ou seja, cujas distâncias entre os objetos do espaço são sempre números inteiros.
Como exemplo, vamos pensar no espaço métrico que representa pontos em um mapa. Lembrando que todo espaço métrico possui uma métrica específica que o define, precisamos escolher muito bem qual a métrica a ser usada neste exemplo para que ele seja elegível à aplicação de uma árvore BK. Se escolhermos a distância Euclideana (linha reta entre dois pontos), teremos uma métrica cujos valores podem variar de maneira contínua, em outras palavras, números reais. Entretanto, se escolhermos como métrica o número de quarteirões a serem percorridos por inteiro, tal métrica terá apenas valores inteiros e teremos um espaço métrico discreto.
Voltando à nossa aplicação de interesse, a distância de edição de Levenshtein é uma métrica discreta, pois o número de operações a serem realizadas para transforma uma palavra em outra é sempre um número inteiro. Com isso, o espaço métrico que representa um conjunto de palavras cuja distância entre si é calculada pela distância de Levenshtein é um espaço discreto e, portanto, pode ser representado por uma árvore BK.
Para a construção da árvore propriamente dita, basta escolhermos um termo arbitrário (que chamarei de termo de referência) do corpus e calcular a distância de todos os outros termos com relação à referência, e organizar as tuplas (palavra, distância) como uma árvore indexada a partir da distância à referência.
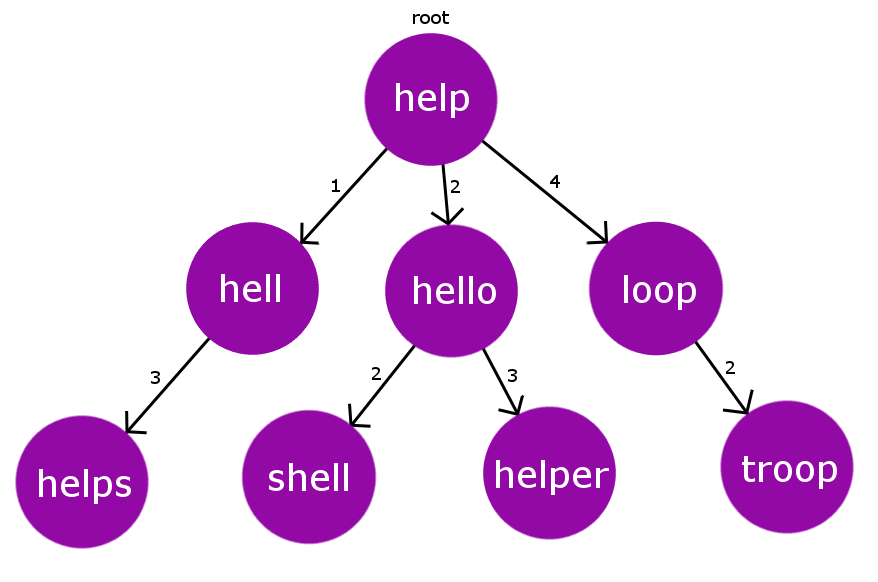 Ilustração de uma árvore BK a partir de algumas palavras em inglês
Ilustração de uma árvore BK a partir de algumas palavras em inglês
Abaixo segue um trecho de código mostrando como criar e usar uma árvore BK a partir de: uma lista de palavras (strings) e uma métrica de distância de edição escolhida (Levenshtein).
# pip install pybktree && pip install python-Levenshtein
from pybktree import BKTree
from Levenshtein import distance as levenshtein_distance
WORDS_LIST = ['car', 'house', 'jar', 'mouse', 'engineer', 'pioneer', 'Jamaica']
tree = BKTree(levenshtein_distance, WORDS_LIST)
Se pedirmos a impressão ordenada da árvore, lembrando que o termo de referência dela é arbitrário, teremos uma lista de palavras ordenadas pelas distância de edição à primeira palavra da lista:
In [1]: print(sorted(tree))
Out[1]: [‘Jamaica’, ‘car’, ‘engineer’, ‘house’, ‘jar’, ‘mouse’, ‘pioneer’]
E se quisermos procurar quais palavras da árvore estão a uma distância de edição menor ou igual a 2 da palavra mouse, teremos como resultado uma lista de tuplas (distância, palavra) ordenadas pela distância:
print(tree.find('mouse'), 2)
[(0, ‘mouse’), (1, ‘house’)]
Como isso se tornaria em um corretor ortográfico?
Dado que agora temos uma árvore onde podemos procurar quaisquer palavras que sejam semelhantes a uma determinada referência, podemos então construir uma árvore com todas as palavras de uma determinada língua (o PT-BR, por exemplo, possui cerca de 381 mil verbetes) e, para cada palavra digitada, checar se existe uma palavra com distância zero (0) para ela e, caso não tenha, sugerir as palavras com menor distância de edição para tal. Simples, não é?
Exemplificando, se eu estivesse escrevendo um texto em inglês e digitasse a palavra gouse. Usando meu exemplo acima, eu poderia procurar as palavras com distância de edição até 3 e obteria o seguinte resultado:
In [1]: tree.find(‘gouse’, 3)
Out[1]: [(1, ‘house’), (1, ‘mouse’)]
Como não foi encontrada nenhuma palavra com distância zero, eu assumiria que essa palavra está errada e sugeriria as palavras house e mouse como as prováveis palavras que deveriam ocupar este espaço.
Obviamente esta é uma visão bastante simplificada de como resolver o problema, afinal existem diversos desafios periféricos à identificação de palavras não existentes:
- Engenharia: percorrer árvores com centenas de milhares de nós em near-real-time. O algoritmo do “caixeiro viajante” é uma boa solução para varrer este tipo de estrutura;
- Semântica: se existem duas palavras com mesma distância, qual a que mais se encaixa no contexto? E se for um erro de digitação, qual das duas palavras estaria mais próxima no quesito “proximidade de teclas”?
- Multi-idiomas: só neste texto eu misturei uns 3 idiomas.
Entretanto, entender como o núcleo da solução funciona lhe permite entender melhor os desafios e como conectar esta solução com todas as funcionalidades e objetivos que você deseja alcançar ao desenvolver tal aplicação.
Referências
- https://en.wikipedia.org/wiki/Metric_space
- https://pt.wikipedia.org/wiki/Desigualdade_triangular
- https://www2.unifap.br/matematica/files/2017/01/Francinor-m%c3%a9trico-completos-e-teorema-de-Banach-steinhuas.pdf
- http://www.ppgia.pucpr.br/~alceu/mestrado/edit_distance.pdf
- https://en.wikipedia.org/wiki/BK-tree
- https://pt.wikipedia.org/wiki/Problema_do_caixeiro-viajante